In our work recently on Element Web (specifically attempting to replace our encryption code with our cross-platform Rust implementation) we’ve noticed some strange behaviour with the performance of our Indexed DB queries.
We’ve been aware of some slowdowns, and wondered whether it was related to the locks we take in the Rust code (which is compiled to WASM for this project), but actually we’ve tracked the latest problems down to time spent inside Indexed DB queries.
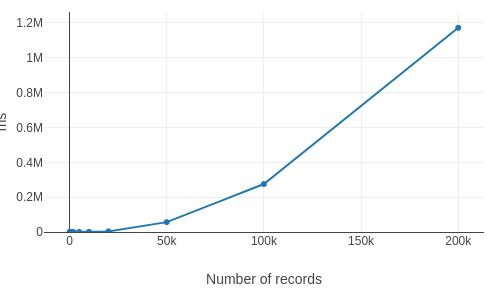
The first surprising thing we found was that several of our slow queries were just counting the number of records in a store. As we dug deeper, we began to suspect that the size of the values we were storing was affecting performance.
I designed a simple test page and we measured some results. You can look at interactive graphs and and record on your own device here: artificialworlds.net/indexed-db-perf. I am hoping to expand this page to more devices and more operations over time, so do check back and/or contribute results. Source code is at codeberg.org/andybalaam/indexed-db-perf.
Note that my analysis is based on widely-available browsers in January 2024, and may become out-of-date.
Here are my conclusions so far.
Headline 1: counting the records in your store can be slow
If we have large keys or values, and we try find out how many records there are in a store containing 200K of them, it will be very slow (6 seconds on my Chromium).
Try to avoid counting records when you can, and consider caching the count in your own code if you need it often.
The slowness of counting probably also indicates that operations that walk all records will also be slow, so think carefully about when and whether you need to do that, and expect to provide feedback to your users when you do it.
Don’t count or walk all records unless you have to.
Headline 2: long keys hurt performance
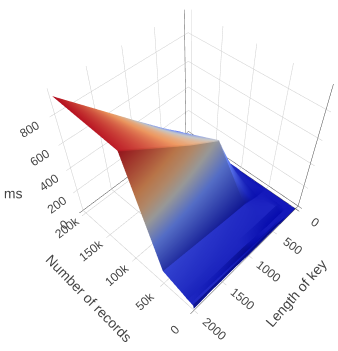
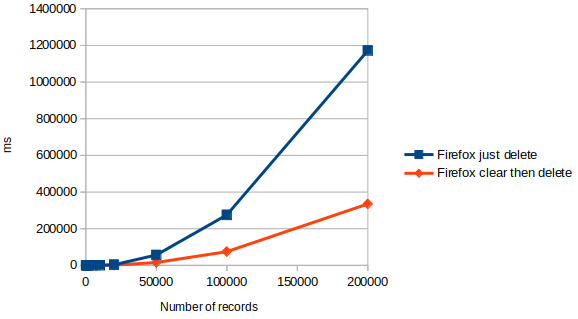
On Firefox, as keys get longer, performance with large numbers of records becomes slower.
The time it takes to count records grows linearly with the length of the keys, and becomes large when keys go over 50 bytes (500 bytes in Firefox).
The shorter your keys, the better.
Headline 3: large values hurt performance
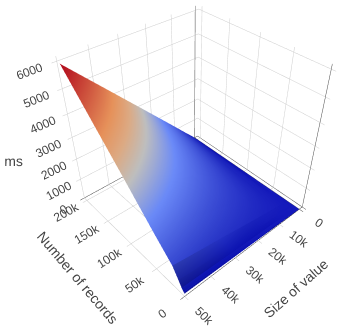
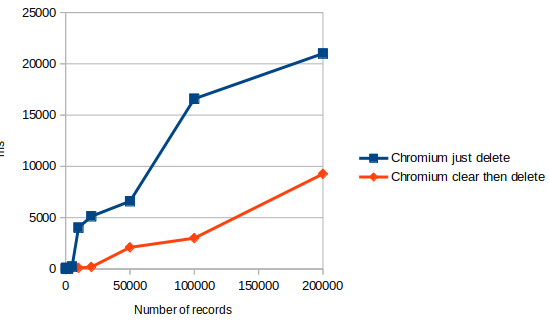
On Chrome, as values get larger, performance with large numbers of records becomes slower.
The time it takes to count records grows linearly with the size of the values you are storing, and becomes large when values go over 1K in size (10K in Firefox).
The smaller your values, the better.
Headline 4: the number of records matters
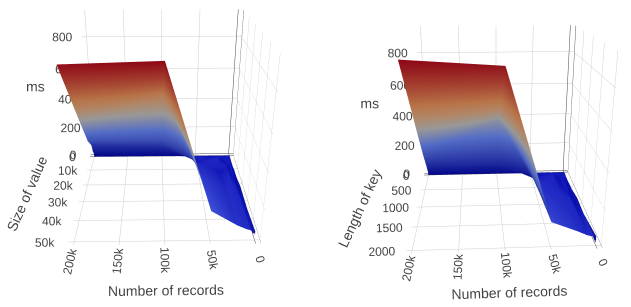
On Firefox over 50K records (with large keys or values), performance degrades rapidly.
If you are storing large values (> 1K) or large keys (> 50 bytes), and you need to walk all records regularly, you should probably try to keep the number of records below 50K if you want interactive performance – over that it rapidly increases to the order of seconds.
In Firefox on Intel, it does seem reasonably stable after 50K, though, so if you exclusively target Firefox on Intel, larger stores are feasible, but you will need to manage the user experience around these ~1 second delays.
In Chromium, performance continues to degrade as the number of records increases. It reaches truly terrible times (6 seconds) with large keys (2000 bytes) and large numbers (200K).
Keep below 50K records if you can.
Headline 5: Indexed DB performance is currently very poor on Apple M1
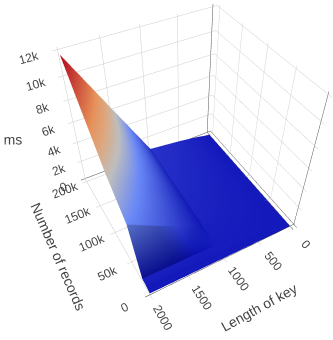
Chrome on Apple M1 hardware takes 12 seconds to perform operations that take 2.5 seconds on Intel.
Firefox’s indexed DB performance on Apple M1 is ~10 times slower than on Intel, taking 8 seconds to count 200K large records.
Chrome’s performance with large keys (> 1000 bytes) is fairly catastrophic when the number of rows approaches 50K. It takes 12 seconds to count 200K records with keys of length 2000, ~6x slower than on Intel.
Both browsers on M1 hit a wall at about 50K records, where their performance with either large keys or large values rapidly degrades to almost unusable levels. The only option for decent performance is to keep keys short and values small.
Test on Apple M1 – it has a serious problem right now!
Observation: Firefox faster than Chromium
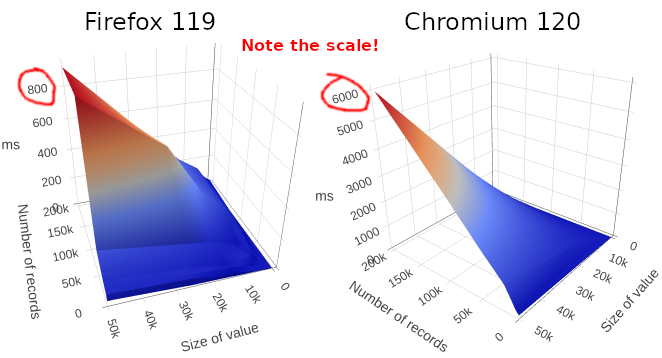
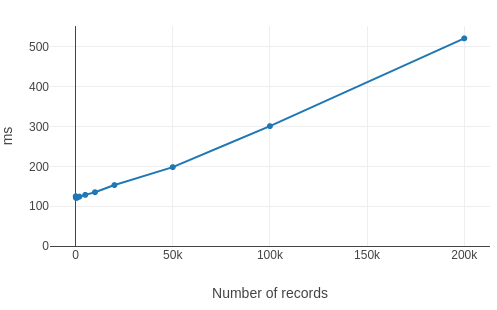
Chrome takes 6 seconds to count large numbers of large values, and Firefox takes 0.8 seconds to do the same thing.
At time of writing, Firefox’s Indexed DB appears to be much faster than Chromium’s when dealing with large numbers of records. In some scenarios, over 7 times faster.
Side note: string values are better than arrays of numbers
Update: see Don’t store arrays of numbers in Indexed DB – use base64 instead.
I don’t have the formal evidence for this because I ran out of time for my investigation, but my initial exploration suggests that encoding a string as an array of numbers, one for each character, slows down performance by over 10 times.
(I think) you should use strings instead of arrays of numbers.
Conclusions
Watch out for Apple M1!
Meanwhile, if you need to improve the performance of your Indexed DB-based web site, you have three options:
- Store fewer records,
- Reduce the size of the records, or
- Reduce the length of the keys.
1 and 2 are probably harder than 3. So definitely consider 3 first.
If you keep key length and value length small, you can have lots of records.
Explore the graphs here: artificialworlds.net/indexed-db-perf
See also: Don’t store arrays of numbers in Indexed DB – use base64 instead and Deleting an Indexed DB store can be incredibly slow on Firefox.