Series: operations, images, opacity
I want to remodel the desktop UI of my game Rabbit Escape to be more convenient and nicer looking, so I took a new look at game-loop-style graphics rendering onto a canvas in a Java 2D (Swing) UI.
For more on images, see the next post.
Specifically, how fast can it be, and what pitfalls should I avoid when I’m doing it?
Results
- Larger windows are (much) slower
- Resizing images on-the-fly is very slow, even if they are the same size every time
- Drawing small images is fast, but drawing large images is slow
- Drawing rectangles is fast
- Drawing text is fast
- Drawing Swing widgets in front of a canvas is fast
- Creating fonts on-the-fly is a tiny bit slow
Code
You can find the full code (written in Kotlin) at gitlab.com/andybalaam/java-2d-performance.
Basically, we make a JFrame and a Canvas and tell them not to listen to repaints (i.e. we control their drawing).
val app = JFrame()
app.ignoreRepaint = true
val canvas = Canvas()
canvas.ignoreRepaint = true
Then we add any buttons to the JFrame, and the canvas last (so it displays behind):
app.add(button)
app.add(canvas)
Now we make the canvas double-buffered and get hold of a buffer image for it:
app.isVisible = true
canvas.createBufferStrategy(2)
val bufferStrategy = canvas.bufferStrategy
val bufferedImage = GraphicsEnvironment
.getLocalGraphicsEnvironment()
.defaultScreenDevice
.defaultConfiguration
.createCompatibleImage(config.width, config.height)
Then inside a tight loop we draw onto the buffer image:
val g2d = bufferedImage.createGraphics()
try
{
g2d.color = backgroundColor
g2d.fillRect(0, 0, config.width, config.height)
... the different drawing operations go here ...
and then swap the buffers:
val graphics = bufferStrategy.drawGraphics
try {
graphics.drawImage(bufferedImage, 0, 0, null)
if (!bufferStrategy.contentsLost()) {
bufferStrategy.show()
}
} finally {
graphics.dispose()
}
} finally {
g2d.dispose()
}
Results
Baseline: some rectangles
I decided to compare everything against drawing 20 rectangles at random points on the screen, since that seems like a minimal requirement for a game.
My test machine is an Intel Core 2 Duo E6550 2.33GHz with 6GB RAM and a GeForce GT 740 graphics card (I have no idea whether it is being used here – I assume not). I am running Ubuntu 18.04.1 Linux, OpenJDK Java 1.8.0_191, and Kotlin 1.3.20-release-116. (I expect the results would be identical if I were using Java rather than Kotlin.)
I ran all the tests in two window sizes: 1600×900 and 640×480. 640×480 was embarrassingly fast for all tests, but 1600×900 struggled with some of the tasks.
Drawing rectangles looks like this:
g2d.color = Color(
rand.nextInt(256),
rand.nextInt(256),
rand.nextInt(256)
)
g2d.fillRect(
rand.nextInt(config.width / 2),
rand.nextInt(config.height / 2),
rand.nextInt(config.width / 2),
rand.nextInt(config.height / 2)
)
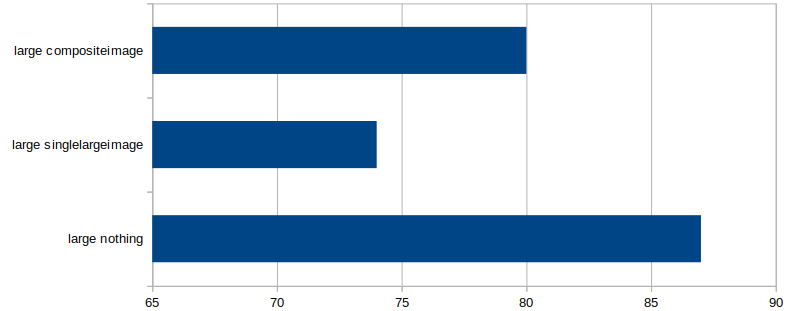
In the small window, the baseline (20 rectangles) ran at 553 FPS. In the large window it ran at 87 FPS.
I didn’t do any statistics on these numbers because I am too lazy. Feel free to do it properly and let me know the results – I will happily update the article.
Fewer rectangles
When I reduced the number of rectangles to do less drawing work, I saw small improvements in performance. In the small window, drawing 2 rectangles instead of 20 increased the frame rate from 553 to 639, but there is a lot of noise in those results, and other runs were much closer. In the large window, the same reduction improved the frame rate from 87 to 92. This is not a huge speed-up, showing that drawing rectangles is pretty fast.
Adding fixed-size images
Drawing pre-scaled images looks like this:
g2d.drawImage(
image,
rand.nextInt(config.width),
rand.nextInt(config.height),
null
)
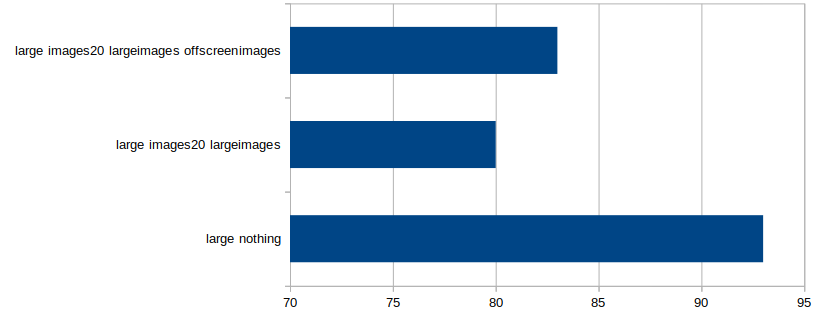
When I added 20 small images (40×40 pixels) to be drawn in each frame, the performance was almost unchanged. In the small window, the run showing 20 images per frame (as well as rectangle) actually ran faster than the one without (561 FPS versus 553), suggesting the difference is negligible and I should do some statistics. In the large window, the 20 images version ran at exactly the same speed (87 FPS).
So, it looks like drawing small images costs almost nothing.
When I moved to large images (400×400 pixels), the small window slowed down from 553 to 446 FPS, and the large window slowed from 87 to 73 FPS, so larger images clearly have an impact, and we will need to limit the number and size of images to keep the frame rate acceptable.
Scaling images on the fly
You can scale an image on the fly as you draw onto a Canvas. (Spoiler: don’t do this!)
My code looks like:
val s = config.imageSize
val x1 = rand.nextInt(config.width)
val y1 = rand.nextInt(config.height)
val x2 = x1 + s
val y2 = y1 + s
g2d.drawImage(
unscaledImage,
x1, y1, x2, y2,
0, 0, unscaledImageWidth, unscaledImageHeight,
null
)
Note the 10-argument form of drawImage is being used. You can be sure you have avoided this situation if you use the 4-argument form from the previous section.
Note: the resulting image is the same size every time, and the Java documentation implies that scaled images may be cached by the system, but I saw a huge slow-down when using the 10-argument form of drawImage above.
On-the-fly scaled images slowed the small window from 446 to 67 FPS(!), and the large window from 73 to 31 FPS, meaning the exact same rendering took over twice as long.
Advice: check you are not using one of the drawImage overloads that scales images! Pre-scale them yourself (e.g. with getScaledInstance as I did here).
Displaying text
Drawing text on the canvas like this:
g2d.font = Font("Courier New", Font.PLAIN, 12)
g2d.color = Color.GREEN
g2d.drawString("FPS: $fpsLastSecond", 20, 20 + i * 14)
had a similar impact to drawing small images – i.e. it only affected the performance very slightly and is generally quite fast. The small window slowed from 553 to 581 FPS, and the large window from 87 to 88.
Creating the font every time (as shown above) slowed the process a little more, so it is worth moving the font creation out of the game loop and only doing it once. The slowdown just for creating the font was 581 to 572 FPS in the small window, and 88 to 86 FPS in the large.
Swing widgets
By adding Button widgets to the JFrame before the Canvas, I was able to display them in front. Their rendering and focus worked as expected, and they had no impact at all on performance.
The same was true when I tried adding these widgets in front of images rendered on the canvas (instead of rectangles).
Turning everything up to 11
When I added everything I had tested all at the same time: rectangles, text with a new font every time, large unscaled images, and large window, the frame rate reduced to 30 FPS. This is a little slow for a game already, and if we had more images to draw it could get even worse. However, when I pre-scaled the images the frame rate went up to 72 FPS, showing that Java is capable of running a game at an acceptable frame rate on my machine, so long as we are careful how we use it.
Numbers
Small window (640×480)

| Test |
FPS |
| nothing |
661 |
| rectangles2 |
639 |
| rectangles20 |
553 |
| rectangles20 images2 |
538 |
| rectangles20 images20 |
561 |
| rectangles20 images20 largeimages |
446 |
| rectangles20 images20 unscaledimages |
343 |
| rectangles20 images20 largeimages unscaledimages |
67 |
| rectangles20 text2 |
582 |
| rectangles20 text20 |
581 |
| rectangles20 text20 newfont |
572 |
| rectangles20 buttons2 |
598 |
| rectangles20 buttons20 |
612 |
Large window (1200×900)

| Test |
FPS |
| large nothing |
93 |
| large rectangles2 |
92 |
| large rectangles20 |
87 |
| large rectangles20 images2 |
87 |
| large rectangles20 images20 |
87 |
| large rectangles20 images20 largeimages |
73 |
| large rectangles20 images20 unscaledimages |
82 |
| large rectangles20 images20 largeimages unscaledimages |
31 |
| large rectangles20 text2 |
89 |
| large rectangles20 text20 |
88 |
| large rectangles20 text20 newfont |
86 |
| large rectangles20 buttons2 |
88 |
| large rectangles20 buttons20 |
87 |
| large images20 buttons20 largeimages |
74 |
| large rectangles20 images20 text20 buttons20 largeimages newfont |
72 |
| large rectangles20 images20 text20 buttons20 largeimages unscaledimages newfont |
30 |
Feedback please
Please do get back to me with tips about how to improve the performance of my experimental code.
Feel free to log issues, make merge requests or add comments to the blog post.